











友情链接
理想、华为、小鹏:三种智驾路线,三种“天命在我”
2025/11/21 0:08:32
0浏览
“话说天下大势,分久必合,合久必分”。
一年之前,除了蔚来死磕世界模型,各路智驾玩家合兵一路,都在冲刺端到端的落地。
而到了现在,在端到端的范式之下,智驾局面之分化堪比三国:
理想押宝VLA,华为和蔚来站队世界模型,小鹏则要沿着第二代VLA直接走向L4。
虽然不见明牌的刀光剑影,但桌面下的唇枪舌剑却实在不少。
理想智驾负责人郎咸朋说VLA是可以走向更高级别自动驾驶的,世界模型是为VLA服务的;
华为车BU CEO靳玉志说VLA取巧,并不是走向真正自动驾驶的路径;
小鹏新上任的智驾一号位刘先明则表示,第二代VLA才是当前智驾的最优解。

大家各执一词,都笃定自己才是正确的。
可智驾技术路线究竟最终会收敛在哪里,行业目前仍没有定论。
虽然谁是正确的尚未可知,可它们之间到底有什么区别却是清晰的。
在《大火的VLA,为什么华为不用?》这篇文章中,我们已经讨论了VLA和世界模型的不同。
那么来到本篇文章,我们再聊聊VLA和第二代VLA,以及第二代VLA和世界模型之间的区别。
VL还是V+L?
首先需要明确的是,行业并没有明确地划分出第一代和第二代VLA。
所谓第二代VLA其实是小鹏的一家之言。
VLA大家应该不陌生了,指的就是视觉语言动作。
按照元戎启行CEO周光的说法,VLA的核心能力指的思维链和长时序推理。
而VLA之所以具备思维链和长时序推理,其核心又在于VLA的L,也就是语言。
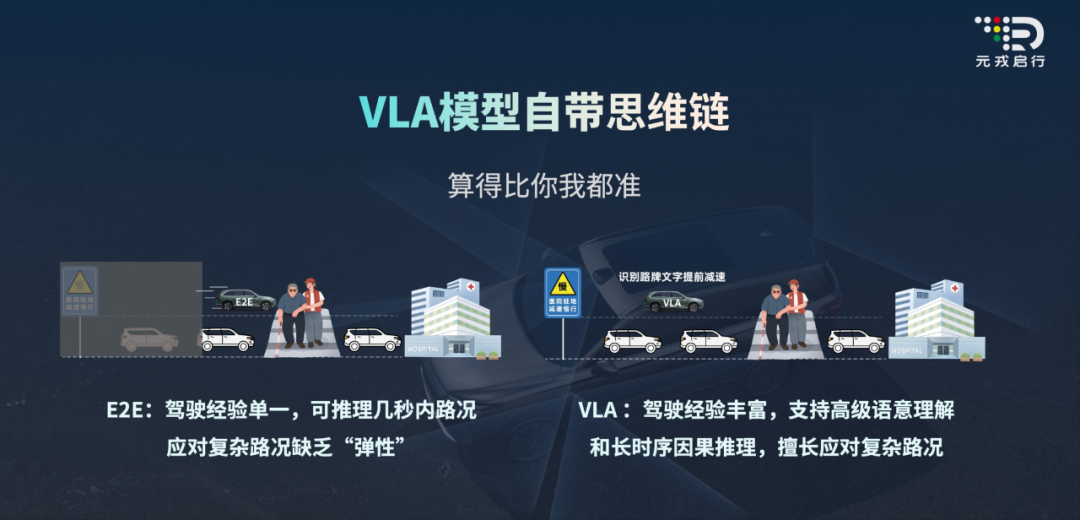
VLA能够将看到的视觉信息转化成自然人类语言,然后再结合车辆状态,做出对应的行动规划和决策。
理想VLA在运行时呈现的CoT推理卡片,就是视觉转化成自然语言的典型呈现。
这样一来,辅助驾驶的可解释性自然大大增强,驾驶者能知道VLA看到了什么、准备怎么做——思想整齐划一,信任感和安全感也就基本到位。
可从何小鹏的角度出发,VLA的问题恰恰就在语言这里。
在何小鹏看来,VLA需要从视觉到语言、从语言到动作这两个环节。
一方面,语言转化能力成了影响辅助驾驶能力的瓶颈;另一方面,两次转化过程中,信息损耗也很高。

所以何小鹏在小鹏科技日上说从第一性原理看,VLA“非常不好”。
既然L不好,小鹏第二代VLA索性就把L部分给砍掉,实现从视觉直接到动作。
如果把L完全砍掉,VLA不就完全变成VA了,跟世界模型无二,怎么还能是VLA?
实际上,按照小鹏自动驾驶中心负责人刘先明的说法,第二代VLA其实还是会有文字,只是文字会被Token化,变成物理语言。
与此同时,VLA的“VL”是从视觉到语言,有一个先后的的转译过程。
第二代VLA中的“VL”则是加法关系,输入的是视觉加Token化语言,然后再到动作。

更浅显地说,有些像做算数题,刚开始算的时候,需要明确加减逻辑、背诵乘法口诀、掰手指头、写草稿纸。
而一旦熟练,往往看一眼就知道计算结果了。
逻辑还是在,只不过被内嵌到那一眼的感觉中去了。
VLA和世界模型什么关系最好?
VLA和世界模型最好的关系应该是什么?
理想在云端部署世界模型进行预训练,然后迭代车端的VLA,所以郎咸朋认为世界模型是为VLA服务的。
世界模型吭哧吭哧练兵,VLA就风风火火打仗。
蔚来在NWM有问必答第三期中说当蔚来世界模型打开语言输入时,它就包含了VLA视觉语言行动模型的特征。
也就是说在蔚来这里,世界模型其实就包含VLA,只是自己想不想用的事,很像将军和小兵的关系。

华为车BU CEO靳玉志又说,华为不会走向VLA的路径,我们认为这样的路径看似取巧,其实并不是走向真正自动驾驶的路径,华为更看重WA,也就是World Action,中间省掉Language这个环节。
华为在云端有WE世界引擎,在车端有WA世界行为模型,跟VLA就是相忘江湖的两条平行线。
到了小鹏这里,VLA和世界模型又发生了新的关系。
何小鹏说第二代VLA既是VLA模型,又是世界模型,本质是理解——推演——生成,最终做出最佳决策。

翻译过来,在第二代VLA这里,VLA和世界模型成了你中有我、我中有你的紧密协作关系。
相比于VLA,世界模型最明显的变化就是外界给出一个刺激,就能是直接从视觉到动作。
就好像向上抛出一个苹果再伸手接过来,它就是一看到便就有动作的反应。
没有人会在那一瞬间根据苹果重量、地球加速度、空气阻力等外界因素,再计算出手的时间、速度、力度。
蔚来智驾负责人任少卿也曾说过,语言是低带宽的,只能描述有限信息,会对世界形成概念认知,却不能建立时空认知,也就是对物理规律的认知。
一辆搭载了FSD V14.1.7的特斯拉最近就遇上了一个典型的需要时空认知的场景。

前方车辆打滑甩尾,直接来了个原地掉头。
当前车刹车灯一亮,特斯拉就进行了减速动作,等汽车有明显的甩尾动作之后,特斯拉的减速力度已经不够,车主及时接管并猛踩刹车才最终避免了碰撞。
车辆如果要成功处理这样瞬息万变的危险场景,必须要对时间、空间的规律有所认知,才能做出类人的下意识反应。
VLA缺乏对物理规律的认知,第二代VLA便通过世界模型将VLA的这块短板给补了上来。

刘先明在小鹏科技日Workshop中放的PPT显示,第二代VLA能够将视频+语言信息经过一定处理后输入到世界模型中,经过强化学习后输出到动作。
写在最后
到了这里,综合以上信息,我们可以列举一下VLA、第二代VLA、世界模型,这三者之间的区别了。

当然,最终是VLA、第二代VLA还是世界模型最强,自然还是靠体验来说话。
透过VLA、第二代VLA和世界模型之间的三国杀,其实也能看到智驾行业来到今天,已经进入了一个缺乏清晰共识的阶段。
智驾的终极答案到底是什么,目前谁也说不清楚。
也许条条大路通L4,大家的坚持都能得到好的结果;也许之后又杀出来一个“司马家”,大家只好再推倒重来。
标签:
举报
全部评论.0
0/150
发布
按热度
按时间
暂无评论,快来抢沙发吧
热门视频
